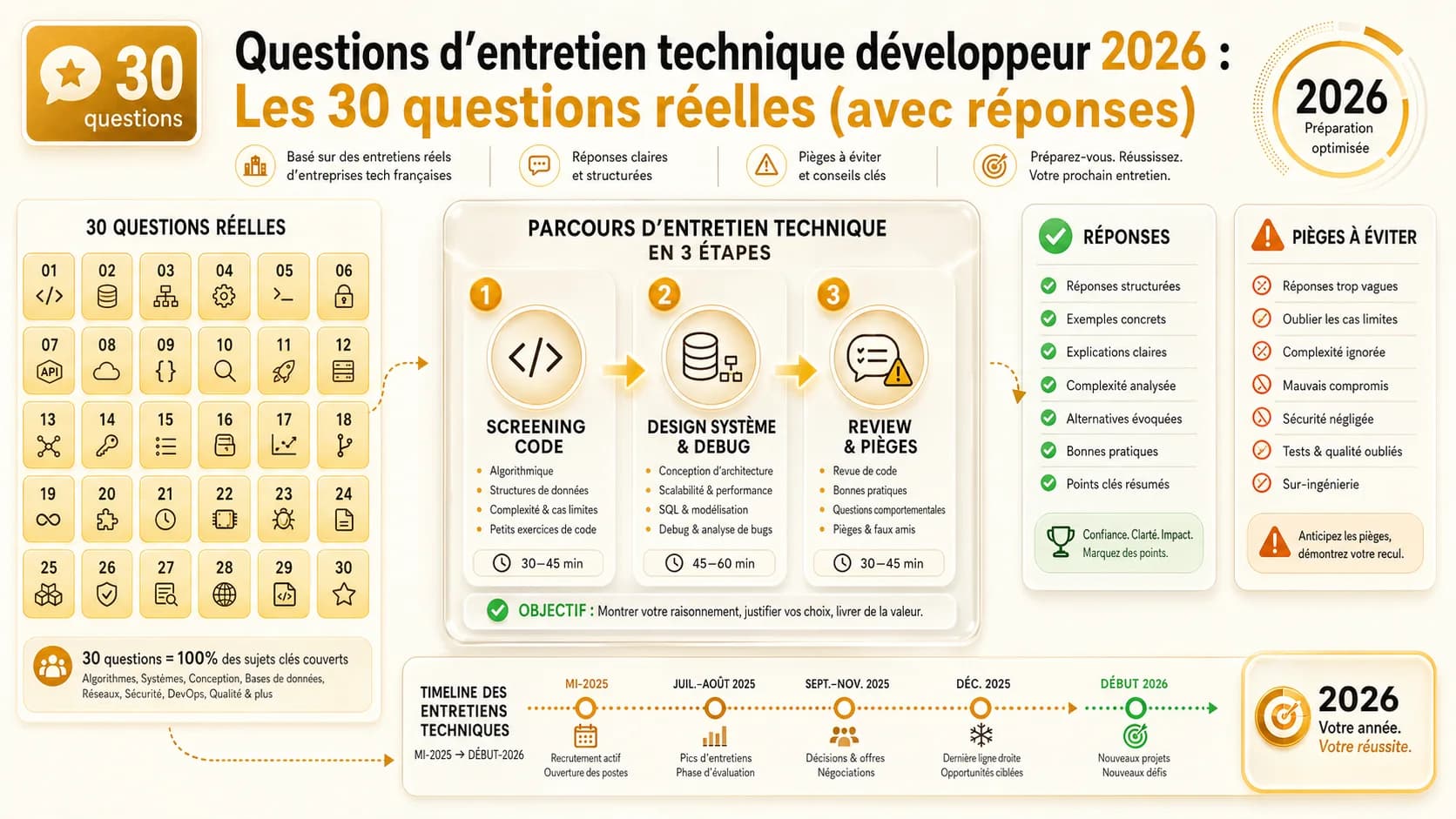
Questions d'entretien technique développeur 2026 : Les 30 questions réelles (avec réponses)
30 questions d'entretien technique posées en 2026 chez Doctolib, Datadog, Criteo, BlaBlaCar. Avec réponses commentées et pièges à éviter.
Équipe carrières.dev
Équipe éditoriale
{/* JSON-LD structured data */} export const jsonLd = { "@context": "https://schema.org", "@type": "Article", "headline": "Questions d'entretien technique développeur 2026 : Les 30 questions réelles (avec réponses)", "description": "30 questions d'entretien technique posées en 2026 chez Doctolib, Datadog, Criteo, BlaBlaCar. Avec réponses commentées et pièges à éviter.", "author": { "@type": "Organization", "name": "Carrières Dev", "url": "https://www.carrieres.dev" }, "publisher": { "@type": "Organization", "name": "Carrières Dev", "url": "https://www.carrieres.dev" }, "datePublished": "2026-03-28", "dateModified": "2026-03-28", "mainEntityOfPage": "https://www.carrieres.dev/blog/questions-entretien-technique-developpeur-2026" };
On a compilé 30 questions réellement posées en entretien technique en France entre mi-2025 et début 2026. Ces questions ont été remontées par des développeurs ayant passé des processus complets chez Doctolib, Datadog, Criteo, BlaBlaCar, Deezer, Back Market et Contentsquare. On ne parle pas de listes théoriques recopiées de blogs américains — on parle de ce qui tombe vraiment dans les scale-ups françaises en 2026.
Chaque question est accompagnée d'une réponse commentée, des pièges classiques à éviter, et de ce que le recruteur cherche réellement à évaluer. L'objectif : que vous arriviez à votre prochain entretien technique avec une longueur d'avance, pas en improvisant.
Si vous cherchez à vous positionner côté rémunération avant de passer ces entretiens, consultez notre grille salariale développeur 2026.
Comment se déroule un entretien technique en France
Le processus standard dans une scale-up ou une grande ESN en France suit un schéma en 4 étapes, avec des variations mineures selon la boîte.
Le format classique :
- Screening RH (30 min) — Motivation, parcours, prétentions salariales, disponibilité. Ce n'est pas technique, mais c'est éliminatoire. Un candidat qui ne sait pas expliquer pourquoi il veut rejoindre cette boîte spécifiquement est écarté dans 60% des cas, selon les données que nous ont partagées des talent acquisition managers.
- Test technique (1-2h) — Soit un live coding en visio (format Doctolib, Datadog), soit un take-home exercise à rendre sous 48-72h (format BlaBlaCar, Back Market). Certaines boîtes proposent le choix.
- Entretien system design / architecture (1h) — Conception d'un système sur tableau blanc (ou Excalidraw). C'est ici que les profils senior se différencient.
- Culture fit / valeurs (30 min) — Questions comportementales, capacité à travailler en équipe, gestion de conflit. Souvent avec un engineering manager.
Différences France vs US :
Le marché français est sensiblement différent du marché américain. On voit beaucoup moins de LeetCode pur (algorithmie hard) et beaucoup plus de conception système et de cas pratiques proches du métier. Chez Doctolib, par exemple, le live coding porte sur un problème métier réaliste (gestion de créneaux de rendez-vous), pas sur un algorithme de graphe abstrait. Chez Datadog, c'est plus proche du format US avec du algo + system design, mais le niveau attendu en algorithmie reste inférieur à celui de Google ou Meta.
Ce que les recruteurs évaluent vraiment :
Le résultat final compte moins que le raisonnement. Un candidat qui verbalise sa réflexion, identifie les edge cases, propose d'abord une solution naive puis l'optimise, et pose les bonnes questions de clarification marquera plus de points qu'un candidat qui sort la solution optimale en silence. Les recruteurs tech que nous avons interrogés sont unanimes : le processus de pensée pèse 60% de la note, le code final 40%.
Partie 1 : Questions de code (10 questions)
Ces questions sont celles qui tombent le plus fréquemment en live coding ou en take-home. Elles testent les fondamentaux du langage, la rigueur, et la capacité à écrire du code propre sous pression.
Q1 : "Implémente une fonction debounce en JavaScript"
Contexte : Posée chez Doctolib et Contentsquare. Question classique qui teste la compréhension des closures, des timers, et du contexte d'exécution.
Réponse :
function debounce(fn, delay) {
let timeoutId;
return function (...args) {
clearTimeout(timeoutId);
timeoutId = setTimeout(() => fn.apply(this, args), delay);
};
}
Ce qui est évalué : La closure qui capture timeoutId, l'utilisation de clearTimeout pour annuler le timer précédent, et fn.apply(this, args) pour préserver le contexte this et les arguments.
Piège classique : Oublier fn.apply(this, args) et écrire simplement fn(args). Ça casse le contexte si le debounce est utilisé comme méthode d'objet, et ça passe les arguments comme un tableau unique au lieu de les spreader.
Q2 : "Quelle est la différence entre == et === ?"
Contexte : Question de screening rapide, souvent en début de live coding pour "chauffer" le candidat.
Réponse : == effectue une coercion de type avant la comparaison (Abstract Equality), tandis que === compare valeur ET type sans coercion (Strict Equality). Exemples concrets :
0 == "" // true — les deux sont convertis en 0
0 === "" // false — number vs string
null == undefined // true — cas spécial de la spec
null === undefined // false — null vs undefined
Ce que le recruteur veut entendre : Que vous utilisez systématiquement === en production, que vous connaissez les cas piégeux de == (notamment null == undefined qui est true), et que vous savez que typeof null === "object" est un bug historique du langage.
Piège : Dire "== compare les valeurs, === compare les types". C'est faux. === compare valeur ET type. == compare les valeurs APRÈS coercion de type.
Q3 : "Explique les closures avec un exemple concret"
Contexte : Posée sous différentes formes chez pratiquement toutes les entreprises. Souvent suivie de "donne-moi un cas d'usage en production".
Réponse : Une closure est une fonction qui "capture" les variables de son scope parent, même après que ce scope a terminé son exécution. En production, le cas d'usage le plus courant est l'encapsulation d'état :
function createCounter(initial = 0) {
let count = initial;
return {
increment: () => ++count,
decrement: () => --count,
getCount: () => count,
};
}
const counter = createCounter(10);
counter.increment(); // 11
counter.increment(); // 12
// count n'est pas accessible directement — encapsulé par la closure
Ce que le recruteur veut entendre : Que vous comprenez le mécanisme de capture lexicale, que vous savez donner un exemple concret (pas juste la définition), et idéalement que vous mentionnez les implications mémoire (une closure garde en vie les variables capturées, ce qui peut causer des memory leaks si mal géré).
Q4 : "Comment fonctionne l'event loop en Node.js ?"
Contexte : Posée chez Datadog et Criteo. Question fondamentale pour tout développeur backend Node.
Réponse : L'event loop est le mécanisme qui permet à Node.js d'être single-threaded tout en gérant des opérations I/O non-bloquantes. Il fonctionne en phases cycliques :
- Timers — exécute les callbacks de
setTimeout/setIntervaldont le délai est écoulé - Pending callbacks — callbacks I/O reportés du cycle précédent
- Poll — récupère les nouveaux événements I/O, exécute leurs callbacks
- Check — exécute les callbacks de
setImmediate - Close callbacks —
socket.on('close', ...)
Entre chaque phase, la microtask queue (Promises, process.nextTick) est vidée intégralement.
Piège classique : Confondre microtasks et macrotasks. process.nextTick et les résolutions de Promise s'exécutent AVANT le passage à la phase suivante de l'event loop. C'est pour ça que ce code affiche "promise" avant "timeout" :
setTimeout(() => console.log("timeout"), 0);
Promise.resolve().then(() => console.log("promise"));
// Output: "promise", "timeout"
Q5 : "Écris une fonction qui détecte les anagrammes"
Contexte : Take-home Criteo et live coding BlaBlaCar. Teste le raisonnement algorithmique de base.
Réponse :
function areAnagrams(a, b) {
if (a.length !== b.length) return false;
const normalize = (str) =>
str.toLowerCase().replace(/\s/g, "").split("").sort().join("");
return normalize(a) === normalize(b);
}
Optimisation attendue : Si le recruteur demande une meilleure complexité, passer de O(n log n) (tri) à O(n) avec un compteur de fréquences :
function areAnagrams(a, b) {
if (a.length !== b.length) return false;
const freq = {};
for (const char of a.toLowerCase()) freq[char] = (freq[char] || 0) + 1;
for (const char of b.toLowerCase()) {
if (!freq[char]) return false;
freq[char]--;
}
return true;
}
Ce que le recruteur veut entendre : Que vous commencez par la solution la plus simple, puis que vous optimisez quand on vous le demande. Montrer que vous connaissez les trade-offs (lisibilité vs performance).
Q6 : "Quelle est la complexité de Array.includes vs Set.has ?"
Contexte : Posée chez Datadog comme question de suivi après un exercice de code.
Réponse : Array.includes() est O(n) — il parcourt le tableau linéairement. Set.has() est O(1) en moyenne — il utilise une table de hachage en interne. Sur un tableau de 100 000 éléments, Set.has est environ 1000x plus rapide pour une recherche unique. Mais la construction du Set est O(n), donc si vous ne faites qu'une seule recherche, ça ne vaut pas le coup de construire un Set.
Piège : Dire que Set.has est "toujours mieux". En réalité, pour un petit nombre de recherches sur un petit tableau, la différence est négligeable et l'overhead de construction du Set peut être supérieur au gain.
Q7 : "Explique la différence entre Promise.all et Promise.allSettled"
Contexte : Posée sous différentes variantes chez Deezer et Back Market.
Réponse :
Promise.all()attend que toutes les promesses soient résolues. Si une seule est rejetée, le tout est immédiatement rejeté (fail-fast).Promise.allSettled()attend que toutes les promesses soient terminées (résolues OU rejetées), et retourne un tableau d'objets{ status: "fulfilled", value }ou{ status: "rejected", reason }.
Cas d'usage :
// Promise.all — quand TOUTES les données sont nécessaires
const [user, orders, preferences] = await Promise.all([
fetchUser(id),
fetchOrders(id),
fetchPreferences(id),
]);
// Promise.allSettled — quand on veut des résultats partiels
const results = await Promise.allSettled([
fetchMainData(),
fetchAnalytics(), // peut échouer sans bloquer
fetchRecommendations(), // idem
]);
const mainData = results[0].status === "fulfilled" ? results[0].value : fallback;
Q8 : "Comment gères-tu les race conditions en async/await ?"
Contexte : Question avancée posée chez Datadog. Différencie les candidats mid-level des seniors.
Réponse : Les race conditions en JavaScript arrivent quand plusieurs opérations asynchrones modifient le même état de façon concurrente. Trois techniques principales :
- AbortController — pour annuler les requêtes obsolètes (typique : search autocomplete) :
let controller;
async function search(query) {
controller?.abort();
controller = new AbortController();
const res = await fetch(`/api/search?q=${query}`, {
signal: controller.signal,
});
return res.json();
}
- Mutex / sémaphore — pour sérialiser les opérations critiques :
let pending = Promise.resolve();
function serialized(fn) {
pending = pending.then(fn).catch(() => {});
return pending;
}
- Versioning — ignorer les résultats obsolètes via un compteur de version :
let version = 0;
async function fetchData() {
const thisVersion = ++version;
const data = await fetch("/api/data").then((r) => r.json());
if (thisVersion !== version) return; // résultat obsolète
setState(data);
}
Q9 : "Refactore ce code"
Contexte : Posée sous différentes formes chez toutes les boîtes. On vous donne un bloc de code "sale" et vous devez l'améliorer.
Exemple donné :
function processUsers(users) {
let result = [];
for (let i = 0; i < users.length; i++) {
if (users[i].age >= 18) {
if (users[i].isActive) {
result.push({
name: users[i].name.toUpperCase(),
email: users[i].email,
status: "eligible",
});
}
}
}
return result;
}
Réponse refactorisée :
const isEligible = (user) => user.age >= 18 && user.isActive;
const toEligibleRecord = (user) => ({
name: user.name.toUpperCase(),
email: user.email,
status: "eligible",
});
function processUsers(users) {
return users.filter(isEligible).map(toEligibleRecord);
}
Ce que le recruteur évalue : extraction de prédicats nommés, remplacement des boucles impératives par des méthodes fonctionnelles (filter, map), et nommage intentionnel. Ne sur-optimisez pas : le recruteur ne s'attend pas à du code "clever", mais à du code lisible et maintenable.
Q10 : "Écris les tests unitaires pour cette fonction"
Contexte : Posée en complément de Q9 ou sur une autre fonction fournie. Teste votre rigueur et votre couverture des edge cases.
Réponse (avec Vitest ou Jest) :
describe("processUsers", () => {
it("retourne les utilisateurs actifs majeurs formatés", () => {
const users = [
{ name: "Alice", email: "a@test.com", age: 25, isActive: true },
{ name: "Bob", email: "b@test.com", age: 30, isActive: false },
];
expect(processUsers(users)).toEqual([
{ name: "ALICE", email: "a@test.com", status: "eligible" },
]);
});
it("retourne un tableau vide si aucun utilisateur éligible", () => {
expect(processUsers([{ name: "X", age: 15, isActive: true }])).toEqual([]);
});
it("gère un tableau vide", () => {
expect(processUsers([])).toEqual([]);
});
it("gère les edge cases d'âge (exactement 18)", () => {
const users = [{ name: "Eve", email: "e@test.com", age: 18, isActive: true }];
expect(processUsers(users)).toHaveLength(1);
});
});
Ce que le recruteur veut voir : le cas nominal, le cas vide, les edge cases (limite d'âge exacte, tous inactifs, tous mineurs), et une structure de test lisible. Mentionner les noms de test descriptifs en français ou en anglais selon la convention de la boîte.
Partie 2 : Questions de conception système (10 questions)
Ces questions testent votre capacité à penser en termes d'architecture, de scalabilité et de trade-offs. Elles arrivent généralement au 3e entretien, face à un staff engineer ou un engineering manager.
Q11 : "Conçois un raccourcisseur d'URL"
Contexte : Le grand classique. Posée chez Criteo et BlaBlaCar. Simple en apparence, elle permet d'explorer de nombreux aspects.
Approche structurée :
- Clarifier les contraintes — Combien d'URLs par jour ? Durée de vie des liens ? Analytics nécessaires ?
- API —
POST /shorten { url }→{ shortUrl }etGET /:code→ redirect 301/302 - Génération du code — Base62 (a-z, A-Z, 0-9) sur 7 caractères = 3,5 milliards de combinaisons. Hash MD5/SHA256 tronqué, ou compteur auto-incrémenté encodé en base62.
- Stockage — Table simple
(code, original_url, created_at, expires_at). Index surcode. PostgreSQL suffit jusqu'à des millions d'URLs. - Scaling — Cache Redis pour les URLs populaires (80% des accès sur 20% des URLs). CDN pour les redirections. Sharding de la DB si nécessaire.
Points bonus : Mentionner le choix 301 (permanent, cacheable) vs 302 (temporaire, permet l'analytics), les collision hash, et la protection contre les URLs malveillantes.
Q12 : "Comment gérerais-tu 10 000 requêtes/seconde sur une API REST ?"
Contexte : Posée chez Datadog. Question ouverte qui teste votre vision globale.
Réponse structurée :
- Load balancing — Nginx ou un ALB devant N instances de l'application. Round-robin ou least connections.
- Caching — Redis pour les données fréquemment lues. Cache HTTP (ETags, Cache-Control) pour les réponses immutables.
- Base de données — Read replicas pour distribuer les lectures. Connection pooling (PgBouncer pour PostgreSQL). Index ciblés sur les colonnes filtrées.
- Horizontal scaling — Application stateless (sessions en Redis, pas en mémoire). Auto-scaling basé sur CPU/mémoire/latence.
- Rate limiting — Token bucket ou sliding window pour protéger l'API. 429 Too Many Requests avec header
Retry-After. - Async processing — Décharger les opérations lourdes vers une queue (RabbitMQ, SQS). Répondre 202 Accepted + webhook/polling.
Ce que le recruteur évalue : Votre capacité à décomposer le problème en couches et à proposer des solutions à chaque niveau, pas une seule "silver bullet".
Q13 : "Explique le pattern CQRS avec un exemple"
Contexte : Posée chez Doctolib en entretien senior.
Réponse : CQRS (Command Query Responsibility Segregation) sépare les opérations de lecture (Query) et d'écriture (Command) en modèles distincts. Exemple concret : sur Doctolib, prendre un rendez-vous (Command) écrit dans une base normalisée PostgreSQL. Afficher les créneaux disponibles (Query) lit depuis une vue dénormalisée optimisée pour la lecture, potentiellement dans Redis ou Elasticsearch.
Avantage : On peut scaler les lectures indépendamment des écritures (les lectures sont souvent 100x plus fréquentes). On peut optimiser chaque modèle pour son cas d'usage.
Inconvénient : Complexité accrue, eventual consistency entre les deux modèles, duplication de données.
Q14 : "Comment implémenterais-tu une file d'attente de jobs ?"
Contexte : Posée chez Back Market et Contentsquare.
Approche :
- Base — Table
jobs (id, type, payload, status, attempts, created_at, locked_at, locked_by). Les workers prennent un job avecUPDATE ... SET status='processing', locked_at=NOW() WHERE status='pending' ORDER BY created_at LIMIT 1 FOR UPDATE SKIP LOCKED. - Retry — Backoff exponentiel avec jitter. Max 3-5 tentatives. Dead letter queue pour les jobs échoués.
- Scaling — Plusieurs workers en parallèle.
FOR UPDATE SKIP LOCKEDempêche deux workers de prendre le même job. - En production — Utiliser Redis (Bull/BullMQ) ou SQS plutôt que de réinventer la roue. Mentionner que vous connaissez les solutions existantes, PUIS montrer que vous comprenez le mécanisme sous-jacent.
Q15 : "Quelle stratégie de cache pour une app e-commerce ?"
Contexte : Posée chez Criteo.
Réponse par couche :
- CDN (Cloudflare, Fastly) — pages produit statiques, images, assets. TTL long (24h+), invalidation par purge.
- Cache applicatif (Redis) — catalogue produit (TTL 5-15 min), résultats de recherche populaires, sessions utilisateur.
- Cache navigateur —
Cache-Control: max-age=31536000, immutablepour les assets hashés.stale-while-revalidatepour les pages. - Ce qu'on ne cache PAS — panier, stock en temps réel, prix dynamiques. Ou alors cache très court (30s) avec invalidation événementielle.
Pattern clé : Cache-aside (l'app vérifie le cache, lit la DB en cas de miss, puis peuple le cache). Pour les données critiques (stock), write-through (écriture simultanée en DB et en cache).
Q16 : "Conçois le système de notification d'une app mobile"
Contexte : Posée chez BlaBlaCar et Deezer.
Architecture :
- Ingestion — Les services émettent des événements (ex:
ride_confirmed,playlist_shared) dans une queue (Kafka/SQS). - Routing — Un service de notification détermine le canal (push, email, SMS, in-app) selon les préférences utilisateur.
- Delivery — Push via Firebase Cloud Messaging (FCM) pour Android, APNs pour iOS. Email via SendGrid/SES. SMS via Twilio.
- Stockage — Table
notifications (user_id, type, channel, content, status, sent_at, read_at). - Rate limiting — Max N notifications par jour par utilisateur pour éviter le spam. Regroupement (digest) des notifications de même type.
Points clés à mentionner : idempotence (ne pas envoyer deux fois la même notification), fallback entre canaux, et respect du RGPD (opt-in explicite pour chaque canal).
Q17 : "Comment migrer une base de données sans downtime ?"
Contexte : Posée chez Doctolib (scale-up critique, pas de maintenance window possible).
Stratégie en 4 phases :
- Dual write — Le code écrit dans l'ancien ET le nouveau schema/table. Les lectures restent sur l'ancien.
- Backfill — Un job batch migre les données historiques vers le nouveau schema. Idempotent, avec reprise possible.
- Switch reads — Les lectures basculent sur le nouveau schema. L'ancien est toujours alimenté en écriture (rollback possible).
- Cleanup — Après validation (quelques jours/semaines), supprimer le dual write et l'ancien schema.
Outil concret : ALTER TABLE ... ADD COLUMN en PostgreSQL est instantané (pas de lock). CREATE INDEX CONCURRENTLY ne bloque pas les écritures. Éviter ALTER TABLE ... ALTER COLUMN TYPE qui réécrit toute la table.
Q18 : "Microservices vs monolithe : quand choisir quoi ?"
Contexte : Question ouverte posée en senior interview chez quasiment toutes les boîtes.
Réponse nuancée :
- Monolithe — Adapté pour les équipes < 15-20 dev, les produits en phase de validation, quand la vélocité de développement prime. Un monolithe bien structuré (modular monolith) est supérieur à des microservices mal découpés.
- Microservices — Justifiés quand les équipes sont autonomes (> 5 équipes), les domaines métier sont clairement séparés, et les besoins de scaling sont hétérogènes (le service de recherche scale différemment du service de paiement).
Ce que le recruteur ne veut PAS entendre : "Les microservices c'est mieux". La bonne réponse est toujours "ça dépend" avec des critères de décision clairs.
Q19 : "Comment gérer l'authentification dans une architecture distribuée ?"
Contexte : Posée chez Contentsquare et Datadog.
Approche :
- Standard — JWT (JSON Web Tokens) signés par un service d'authentification central. Chaque microservice valide le token localement sans appeler le service d'auth.
- Structure du JWT — Header (algo), Payload (user_id, roles, exp, iat), Signature.
- Refresh tokens — JWT access token courte durée (15 min). Refresh token longue durée (7 jours) stocké en httpOnly cookie, utilisé pour obtenir un nouveau access token.
- Révocation — Problème classique du JWT : on ne peut pas le révoquer avant expiration. Solutions : blacklist Redis (vérifié à chaque requête, mais recrée un point central), ou tokens très courts (5 min) avec refresh fréquent.
- Service mesh — Dans une archi mature, l'authentification est gérée au niveau du sidecar proxy (Envoy/Istio) et pas dans chaque service.
Q20 : "Explique les trade-offs de SQL vs NoSQL pour un feed social"
Contexte : Posée chez Deezer.
Réponse :
- SQL (PostgreSQL) — Requête de feed = jointures complexes (posts + auteurs + likes + commentaires). Fiable, ACID, mais les jointures deviennent coûteuses à grande échelle. Fan-out on read : le feed est calculé à chaque lecture.
- NoSQL (Cassandra, DynamoDB) — Feed pré-calculé par utilisateur (fan-out on write). Chaque publication insère une entrée dans le feed de chaque follower. Lectures ultra-rapides (clé de partition = user_id), mais les écritures sont amplifiées (un post d'un compte à 1M de followers = 1M d'écritures).
- Approche hybride — Fan-out on write pour les utilisateurs classiques, fan-out on read pour les comptes à très forte audience (les "célébrités"). C'est l'approche Twitter/X historique.
Trade-off clé : Latence de lecture vs coût d'écriture vs fraîcheur du contenu. Il n'y a pas de bonne réponse universelle — c'est un choix d'architecture qui dépend du ratio lecteurs/auteurs et de la tolérance à la latence.
Partie 3 : Questions comportementales et culture (10 questions)
Ne sous-estimez pas cette partie. Chez les scale-ups françaises, un candidat techniquement solide mais qui rate le culture fit sera écarté. Ces questions utilisent le format STAR (Situation, Task, Action, Result) — préparez vos stories à l'avance.
Q21 : "Parle-moi d'un bug en production que tu as résolu"
Ce que le recruteur évalue : Votre capacité de diagnostic sous pression, votre méthodologie (logs, métriques, reproduction), et votre communication pendant l'incident.
Template STAR :
- Situation — Décrivez le contexte (service affecté, impact utilisateur, heure)
- Task — Votre rôle spécifique (on-call, appelé en renfort, discovery)
- Action — Les étapes concrètes (analyse des logs, hypothèse, fix, rollback, hotfix)
- Result — Temps de résolution, post-mortem, actions préventives mises en place
À ne PAS dire : "C'était la faute de X". Jamais de blame. Focalisez sur le processus et les apprentissages.
Q22 : "Comment gères-tu un désaccord technique avec un collègue ?"
Bonne réponse : "Je cherche d'abord à comprendre son raisonnement en posant des questions. Si le désaccord persiste, on écrit les pour/contre de chaque approche, on définit des critères objectifs (performance, maintenabilité, délai), et on tranche ensemble. Si on ne converge pas, on escalade à un lead ou on fait un spike technique pour comparer empiriquement."
À ne PAS dire : "Je m'impose car j'ai plus d'expérience" ou "Je cède pour éviter le conflit".
Q23 : "Quel est ton processus de code review ?"
Points clés à mentionner :
- Lire le ticket/la PR description avant le code
- Vérifier la couverture de test
- Chercher les bugs logiques, pas les préférences stylistiques (c'est le rôle du linter)
- Feedback constructif : "As-tu envisagé X ?" plutôt que "C'est faux"
- Approbation partielle si le gros est OK et que le reste est mineur
Q24 : "Comment restes-tu à jour techniquement ?"
Bonne réponse : Mentionnez des sources concrètes — newsletters (TLDR, JavaScript Weekly), blogs tech (engineering blog de la boîte où vous postulez), conférences (Devoxx France, dotJS), side projects, contributions open source. Montrez que c'est une habitude régulière, pas un effort ponctuel.
À ne PAS dire : "Je lis les docs". C'est trop vague et ne montre aucune initiative.
Q25 : "Parle-moi d'un projet qui a échoué"
Ce que le recruteur évalue : Votre capacité d'introspection et votre humilité. Tout le monde a des échecs — ce qui compte, c'est ce que vous en avez tiré.
Template : Décrivez le projet, ce qui a mal tourné (mauvaise estimation, scope creep, techno inadaptée), ce que vous auriez fait différemment, et ce que vous avez concrètement changé dans votre façon de travailler depuis.
Q26 : "Comment estimes-tu le temps d'une feature ?"
Bonne réponse : "Je décompose en sous-tâches (design, implémentation, tests, review, déploiement). J'estime chaque sous-tâche. J'ajoute un buffer de 20-30% pour les imprévus. Je compare avec des features similaires déjà livrées. Et je communique une fourchette (optimiste/réaliste/pessimiste), pas un chiffre unique."
Point bonus : Mentionner que les estimations sont par nature incertaines et que la transparence sur l'incertitude est plus utile qu'une fausse précision.
Q27 : "Quelle est ta plus grande force technique ? Ta plus grande faiblesse ?"
Piège : La faiblesse déguisée en force ("je suis trop perfectionniste"). Le recruteur a entendu ça 500 fois. Donnez une vraie faiblesse avec un plan d'action concret. Exemple : "Je manque d'expérience en infrastructure/Kubernetes. Pour y remédier, j'ai suivi la certification CKA et je fais du pair programming avec notre SRE une fois par semaine."
Q28 : "Comment intègres-tu l'IA dans ton workflow ?"
Contexte : Question nouvelle en 2025-2026, posée de plus en plus fréquemment.
Bonne réponse : Soyez concret. "J'utilise GitHub Copilot pour le code boilerplate et les tests. J'utilise Claude/ChatGPT pour le debugging (je colle le stack trace + le contexte) et pour explorer des approches architecturales. Mais je relis systématiquement, je ne merge jamais du code généré sans l'avoir compris et testé."
À ne PAS dire : "Je n'utilise pas l'IA" (vous passez pour un dinosaure) ou "L'IA écrit tout mon code" (vous passez pour quelqu'un qui ne code pas vraiment).
Q29 : "Parle-moi d'une décision d'architecture que tu regrettes"
Ce que le recruteur évalue : Votre recul technique et votre capacité à apprendre de vos erreurs. Les bons ingénieurs ont des regrets d'architecture — c'est le signe qu'ils ont grandi.
Exemples crédibles : Avoir choisi un microservice trop tôt, une base NoSQL quand SQL suffisait, un framework hype qui est mort 2 ans plus tard, ou pas assez investi dans les tests dès le départ.
Q30 : "Pourquoi veux-tu quitter ton poste actuel ?"
Règle absolue : Ne JAMAIS critiquer votre employeur actuel. Même si c'est vrai. Le recruteur se demandera ce que vous direz de SA boîte dans 2 ans.
Bonne réponse : Formulez en termes de ce que vous CHERCHEZ (plus de responsabilité, un domaine technique qui vous passionne, un produit qui a un impact, une stack moderne), pas en termes de ce que vous FUYEZ.
Stratégie de préparation en 2 semaines
Vous avez décroché un entretien dans 2 semaines. Voici un plan réaliste, pas un programme de bootcamp irréaliste.
Semaine 1 : Fondamentaux
- Jours 1-2 — Révisez les structures de données fondamentales : arrays, hash maps, stacks, queues, arbres binaires, graphes. Pas besoin de les implémenter from scratch, mais vous devez connaître les complexités et les cas d'usage.
- Jours 3-4 — Faites 15-20 problèmes LeetCode Easy/Medium. Focalisez sur les patterns : two pointers, sliding window, hash map lookup, BFS/DFS. En France, on dépasse rarement le niveau Medium.
- Jours 5-7 — Révisez les fondamentaux web : HTTP (méthodes, status codes, headers), REST, SQL (JOIN, GROUP BY, indexes, EXPLAIN), et les bases de votre framework principal (React, Node, Spring, Django).
Semaine 2 : System design et soft skills
- Jours 8-9 — Pratiquez 3-4 exercices de system design. Utilisez le System Design Primer sur GitHub (gratuit, excellent). Chronométrez-vous : 5 min de clarification, 10 min de high-level design, 15 min de deep dive.
- Jours 10-11 — Mock interviews. Faites-vous interviewer par un ami dev, ou utilisez Pramp (gratuit) / interviewing.io. Le format live est très différent de coder seul devant son écran.
- Jours 12-13 — Préparez vos 5-6 stories STAR. Relisez les questions comportementales ci-dessus et écrivez vos réponses. Répétez-les à voix haute — le jour J, vous devez être fluide, pas en train de chercher vos mots.
- Jour 14 — Repos. Relisez vos notes, mais ne faites rien d'intense. Arrivez frais.
Ressources recommandées :
- LeetCode — Top 50 questions classées par pattern (Neetcode 150 est une excellente sélection)
- System Design Primer — La bible gratuite du system design
- Tech Interview Handbook — Checklists et templates de réponses
- Carrières Dev — Entreprises — Fiches détaillées des processus d'entretien par boîte
FAQ
Combien de temps se préparer pour un entretien technique ?
Minimum 2 semaines, idéalement 4 si vous n'avez pas passé d'entretien depuis longtemps. La majorité du temps doit aller sur la pratique active (résoudre des problèmes, faire des mock interviews), pas sur la lecture passive. Un ratio 70% pratique / 30% théorie est un bon repère.
Faut-il savoir le LeetCode en France ?
Beaucoup moins qu'aux US. Les scale-ups françaises (Doctolib, BlaBlaCar, Back Market) posent des problèmes de niveau Easy à Medium, souvent contextualisés métier. Les GAFAM à Paris (Google, Meta) suivent le format US classique avec du Medium à Hard. Adaptez votre préparation à la cible.
Peut-on refuser un test technique à la maison ?
Oui, c'est votre droit. Mais c'est souvent éliminatoire par défaut. Si vous refusez, proposez une alternative (live coding, pair programming sur votre code open source, discussion technique approfondie). Certaines boîtes (Doctolib notamment) proposent le choix entre take-home et live coding.
Comment négocier après un entretien réussi ?
Attendez l'offre écrite. Ne donnez jamais votre salaire actuel (c'est illégal de le demander dans certains pays, et en France c'est de mauvaise pratique). Donnez une fourchette basée sur le marché — consultez notre grille salariale. Négociez le package global (salaire fixe + variable + equity/BSPCE + avantages) et pas uniquement le fixe.
Les entretiens sont-ils différents en ESN vs scale-up ?
Oui, significativement. En ESN (Capgemini, Sopra, Atos), le processus est plus court (1-2 entretiens), moins technique (focus sur l'expérience et la disponibilité), et la décision est souvent prise par un commercial, pas un tech. En scale-up, le processus est plus long (3-5 étapes), plus technique, et la barre est plus haute. Le salaire aussi — consultez nos comparatifs par type d'entreprise.
Article mis à jour en mars 2026. Les questions sont issues de témoignages de candidats ayant passé des entretiens entre juin 2025 et mars 2026. Pour des fiches d'entretien spécifiques par entreprise, consultez notre annuaire entreprises.
Autres projets Doved Studio
Quelques outils complémentaires du même studio qui peuvent vous intéresser:
- Simuler Ma Retraite: Simulez ce que vous coûtera la retraite française et préparez un plan concret.
- Akademos: Tuteur IA pour enfants de 5 à 17 ans, aligné sur le programme français.
- Ralphable: Generate structured Claude Code skills that iterate until pass/fail criteria are met.
- Doved Studio: Studio indie derrière cette app et une dizaine d'autres outils.
Qu'avez-vous pense de cet article ?
Commentaires (0)
Connectez-vous pour laisser un commentaire
Se connecterSoyez le premier a commenter cet article !